人工智能賦能的智能化軟件測試 基礎軟件開發的新范式
在當今軟件產業高速發展的時代,軟件系統的復雜性、規模和迭代速度都達到了前所未有的高度。傳統的軟件測試方法,高度依賴人工設計用例、執行腳本和分析結果,在面對現代復雜軟件,尤其是底層基礎軟件時,愈發顯得力不從心。效率瓶頸、覆蓋率不足、對未知缺陷的探測能力有限等問題日益凸顯。與此人工智能技術的迅猛發展,特別是機器學習、深度學習、自然語言處理等領域的突破,為軟件測試的智能化變革提供了強大的技術引擎。將人工智能深度融入軟件測試全流程,構建“智能化軟件測試”體系,已成為提升基礎軟件開發質量與效率的必然選擇。
智能化軟件測試的核心,在于利用AI技術模擬、增強乃至超越人類測試專家的部分認知與執行能力。在基礎軟件開發這一特定領域,其應用價值尤為顯著。基礎軟件,如操作系統內核、數據庫系統、編譯器等,通常具有代碼規模龐大、邏輯結構復雜、對穩定性和性能要求極高等特點。傳統的測試方法需要耗費巨大的人力與時間成本才能達到較高的測試充分性。而AI的引入,可以從以下幾個關鍵環節帶來革命性提升:
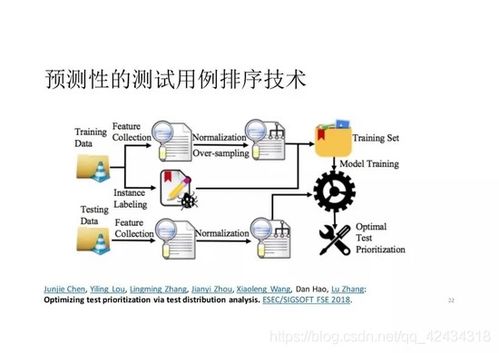
在測試用例的智能生成與優化方面。AI可以通過學習程序代碼、歷史缺陷數據、規格說明書甚至用戶行為日志,自動生成大量、高針對性的測試用例。例如,基于模糊測試(Fuzzing)技術,結合強化學習算法,可以動態調整測試輸入的數據生成策略,更高效地探索程序的深層狀態空間和邊界條件,從而發現那些隱蔽的、需要特定條件觸發的安全漏洞或崩潰缺陷。對于基礎軟件中復雜的API接口和協議,AI能夠理解其語義約束,生成既符合語法又富含“攻擊性”的測試數據,大幅提升測試的深度和廣度。
在測試執行的智能調度與優先排序方面。面對成千上萬的測試用例,如何高效利用計算資源、快速反饋最可能發現缺陷的測試結果,是一個關鍵問題。AI模型可以預測測試用例的故障檢測概率、執行時間以及對代碼變更的敏感度,從而實現測試套件的動態優先級排序和選擇性執行。在持續集成/持續交付(CI/CD)流水線中,這種智能調度能夠確保在資源有限的情況下,優先運行風險最高的測試,加速開發反饋循環,這對于追求高穩定性的基礎軟件迭代至關重要。
在測試結果的智能分析與缺陷預測方面。AI能夠自動化處理海量的測試執行日志、程序崩潰核心轉儲(Core Dump)、靜態代碼掃描報告等。通過模式識別和異常檢測技術,它可以自動對測試失敗進行分類、聚類,并初步定位可能的根因,甚至將相似的缺陷關聯起來,極大減輕測試人員分析海量結果的工作負擔。更進一步,基于代碼變更歷史、開發者協作網絡、代碼復雜度度量等特征,AI可以構建缺陷預測模型,在代碼提交或構建階段就標識出高風險模塊,實現測試資源的精準投放,變“事后檢測”為“事前預防”。
在測試維護的智能適應方面。基礎軟件處于持續演進中,代碼的每一次變更都可能使部分原有測試用例失效(即產生“測試壞味道”)。AI可以自動分析代碼變更與測試用例之間的影響關系,識別出需要更新或廢棄的測試,并輔助甚至自動完成測試用例的演化與修復,保證測試資產與軟件版本同步,維持測試套件的長期健康度。
將人工智能應用于基礎軟件的智能化測試也面臨獨特挑戰。基礎軟件對正確性的要求是“極端”的,一個微小的錯誤可能導致災難性后果。因此,AI模型本身的可解釋性、可靠性和安全性必須得到高度重視。我們無法完全信任一個“黑盒”AI模型做出的測試決策。如何構建可解釋的AI測試模型,如何確保AI生成的測試用例本身不引入偏見或盲區,如何將形式化驗證等嚴謹方法與AI測試相結合,是當前研究和實踐的前沿課題。
高質量訓練數據的獲取也是一大難點。基礎軟件領域的缺陷數據往往稀少且敏感,公開數據集不足。需要創新性地利用代碼合成、遷移學習等技術來緩解數據依賴問題。培養既懂軟件工程、測試理論,又掌握AI技術的復合型人才,是推動這一范式落地的關鍵。
智能化軟件測試與人工智能基礎軟件開發將形成一個相輔相成的共生循環。一方面,更先進的AI技術(如大語言模型)將持續賦能測試,實現更接近人類直覺的測試場景理解與創造。另一方面,強大、可靠的智能化測試工具本身,也將成為開發下一代AI基礎軟件(如AI框架、AI芯片驅動)的核心保障設施。這場由AI驅動的測試變革,正在深刻重塑基礎軟件開發的質效標準與工程實踐,推動整個軟件產業向更高水平的自動化、智能化邁進。
如若轉載,請注明出處:http://m.agkj8ai.cn/product/18.html
更新時間:2026-06-09 03:11:50